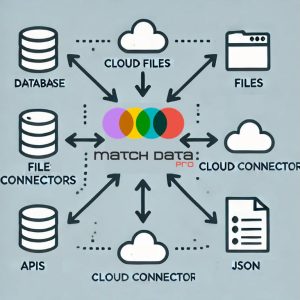
Identify and handle issues such as duplicates, outliers, missing values, formatting inconsistencies in the data, and build a clean dataset through operations such as deduplication, padding, filtering, and correction. Data cleaning is a key step to ensure accurate statistical results, effective algorithmic models, and reliable reporting, and it is a fundamental part of data asset management.